R aplicado a la ECH
Setiembre 2020
Gabriela Mathieu

Creative Commons Attribution 4.0 International License
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
- Definir una función para encontrar un dato faltante
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
- Definir una función para encontrar un dato faltante
- Definir una función para encontrar un caso duplicado
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
- Definir una función para encontrar un dato faltante
- Definir una función para encontrar un caso duplicado
- Introducción al paquete dplyr para manipular un data frame
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
- Definir una función para encontrar un dato faltante
- Definir una función para encontrar un caso duplicado
- Introducción al paquete dplyr para manipular un data frame
- Operadores lógicos y de comparación. Operador %in%.
¿Qué haremos hoy?
- Exportar objetos a archivos RData. Importar archivos RData.
- Definir una función para encontrar un dato faltante
- Definir una función para encontrar un caso duplicado
- Introducción al paquete dplyr para manipular un data frame
- Operadores lógicos y de comparación. Operador %in%.
- Trabajar en proyecto (.Rproj)
RData
Guardar un objeto a un archivo RData
- RData es un formato propio de R.
Guardar un objeto a un archivo RData
- RData es un formato propio de R.
- Sirve para guardar objetos de R. Los archivos ocupan mucho menos espacio que otros formatos.
Guardar un objeto a un archivo RData
- RData es un formato propio de R.
- Sirve para guardar objetos de R. Los archivos ocupan mucho menos espacio que otros formatos.

Guardar un objeto a un archivo RData
La función save() permite guardar un objeto en un archivo RData
# guardar un objeto (data frame) en formato Rsave(ech19, file = "data/ech19.RData")Guardar un objeto a un archivo RData
La función save() permite guardar un objeto en un archivo RData
# guardar un objeto (data frame) en formato Rsave(ech19, file = "data/ech19.RData")Debo escribir el argumento file de lo contrario me dará error porque no es el segundo argumento de la función. Allí especifico el nombre del archivo que voy a crear.
Adicionalmente puede incluir la ruta donde se creará el archivo. Si solo se define el nombre del archivo, se guarda en el directorio de trabajo actual: getwd()
Guardar un objeto a un archivo RData
La función save() permite guardar un objeto en un archivo RData
# guardar un objeto (data frame) en formato Rsave(ech19, file = "data/ech19.RData")Debo escribir el argumento file de lo contrario me dará error porque no es el segundo argumento de la función. Allí especifico el nombre del archivo que voy a crear.
Adicionalmente puede incluir la ruta donde se creará el archivo. Si solo se define el nombre del archivo, se guarda en el directorio de trabajo actual: getwd()
- El nombre del objeto y el archivo pueden coincidir, pero no necesariamente.
Guardar un objeto a un archivo RData
La función save() permite guardar un objeto en un archivo RData
# guardar un objeto (data frame) en formato Rsave(ech19, file = "data/ech19.RData")Debo escribir el argumento file de lo contrario me dará error porque no es el segundo argumento de la función. Allí especifico el nombre del archivo que voy a crear.
Adicionalmente puede incluir la ruta donde se creará el archivo. Si solo se define el nombre del archivo, se guarda en el directorio de trabajo actual: getwd()
- El nombre del objeto y el archivo pueden coincidir, pero no necesariamente.
- Es posible guardar más de un objeto en el mismo archivo RData.
Leer un archivo RData
- La función load() permite cargar archivos RData.
Leer un archivo RData
- La función load() permite cargar archivos RData.
- No lo asigno a ningún objeto a diferencia del resto de las funciones de importación/lectura.
Leer un archivo RData
- La función load() permite cargar archivos RData.
- No lo asigno a ningún objeto a diferencia del resto de las funciones de importación/lectura.
load("data/ech19.RData")- En este caso puedo prescindir de nombrar el argumento file porque es el primero de la función.
Leer un archivo RData
¿Qué pasa si lo asigno a un objeto?
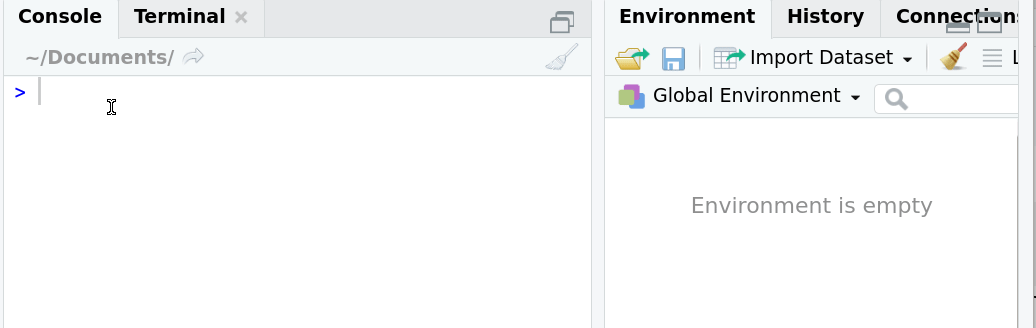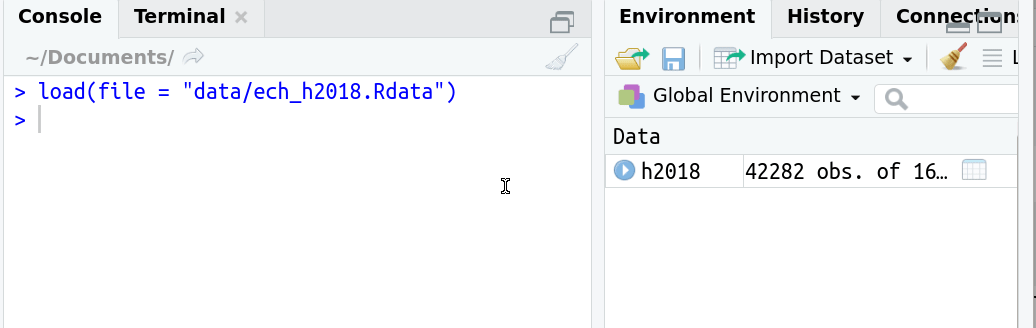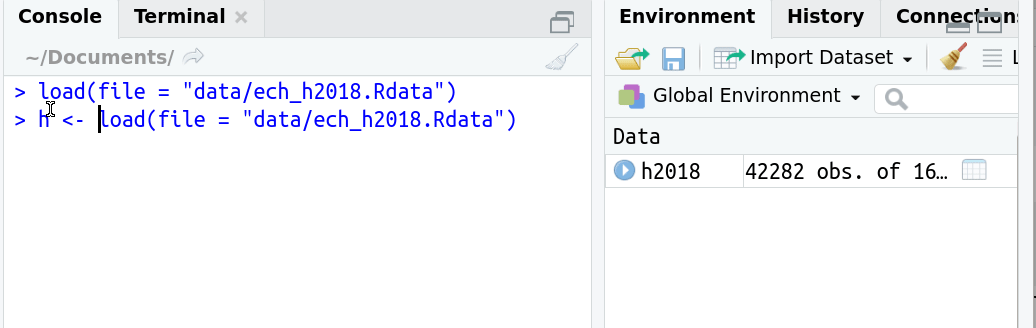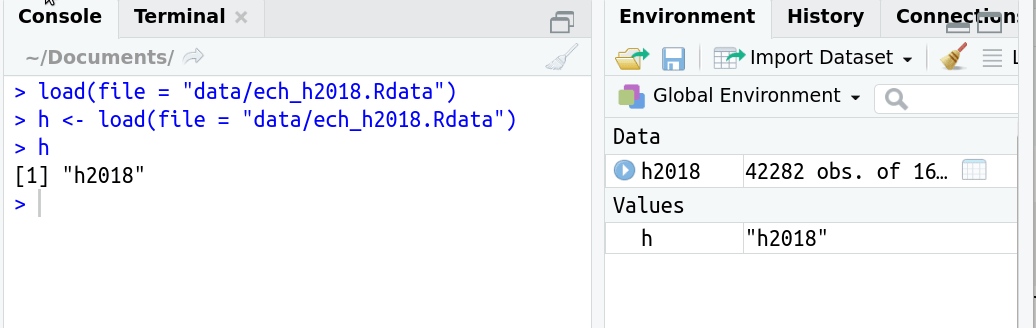
- Si existe como archivo RData tuvo que crearse primero como objeto.
Leo los datos de ECH 2019
Es una nueva sesión así que no tengo los objetos en memoria que tenía ayer.
Voy a usar la función load() que viene en R-base.
load("/home/calcita/Desktop/ech19.RData") #cargo los datosNunca asigno a un objeto cuando uso la función load()
Datos faltantes (NA)
- La función is.na() chequea si hay un dato faltante (NA: not available) para cada elemento de un vector.
Datos faltantes (NA)
- La función is.na() chequea si hay un dato faltante (NA: not available) para cada elemento de un vector.
x <- c(-22, 4, -1, 8, NA)x[1] -22 4 -1 8 NA- ¿Cuántos datos faltantes tiene x?
Datos faltantes (NA)
- La función is.na() chequea si hay un dato faltante (NA: not available) para cada elemento de un vector.
x <- c(-22, 4, -1, 8, NA)x[1] -22 4 -1 8 NA- ¿Cuántos datos faltantes tiene x?
- Devuelve un vector lógico, donde el TRUE indica que no hay dato y el FALSE que sí hay dato.
is.na(x)[1] FALSE FALSE FALSE FALSE TRUEEjemplo: Datos faltantes (NA)
sin_pobpcoac <- is.na(ech19$pobpcoac)Ejemplo: Datos faltantes (NA)
sin_pobpcoac <- is.na(ech19$pobpcoac)- ¿Cuántos son los valores faltantes de
pobpcoac?
table(sin_pobpcoac)sin_pobpcoac FALSE 107871sum(sin_pobpcoac)[1] 0El valor lógico TRUE representa al 1 y el valor FALSE representa al 0 por eso puedo usar la función sum().
Observaciones duplicadas
La función duplicated() determina cuales elementos de un vector o data frame están duplicados, devuelve un vector lógico: TRUE si es duplicado y FALSE en caso contrario.
Observaciones duplicadas
La función duplicated() determina cuales elementos de un vector o data frame están duplicados, devuelve un vector lógico: TRUE si es duplicado y FALSE en caso contrario.
- Compara un elemento del vector con todos los anteriores, va asignando el valor FALSE hasta que se encuentra con un caso duplicado y en este caso le asigna TRUE y sigue comparando.
x <- c(-22, 4, 8, 8, NA)x[1] -22 4 8 8 NAObservaciones duplicadas
La función duplicated() determina cuales elementos de un vector o data frame están duplicados, devuelve un vector lógico: TRUE si es duplicado y FALSE en caso contrario.
- Compara un elemento del vector con todos los anteriores, va asignando el valor FALSE hasta que se encuentra con un caso duplicado y en este caso le asigna TRUE y sigue comparando.
x <- c(-22, 4, 8, 8, NA)x[1] -22 4 8 8 NAduplicated(x)[1] FALSE FALSE FALSE TRUE FALSEEjemplo: observaciones duplicadas
- Chequeo que haya algún caso duplicado, reviso todas las variables
repetidos <- duplicated(ech19) # el argumento es el data framesum(repetidos) # los sumo, recordar: TRUE es 1 y FALSE es 0[1] 0- Chequeo que haya algún valor duplicado en la variable identificatoria de cada caso
repetidos <- duplicated(ech19$numero) # el argumento es una variablesum(repetidos)[1] 65364Si nombro a un objeto igual a uno existente, lo sobreescribo.
dplyr
Manipular datos con dplyr
- El paquete dplyr permite representar la información de un data frame en forma de tabla, donde cada fila representa una observación y cada columna represente una variable.
Manipular datos con dplyr
- El paquete dplyr permite representar la información de un data frame en forma de tabla, donde cada fila representa una observación y cada columna represente una variable.
- dplyr no provee ninguna funcionalidad que no pueda ser realizada con las funciones del paquete base, sin embargo, es más simple y rápido (está escrito en C++).
Manipular datos con dplyr
- El paquete dplyr permite representar la información de un data frame en forma de tabla, donde cada fila representa una observación y cada columna represente una variable.
- dplyr no provee ninguna funcionalidad que no pueda ser realizada con las funciones del paquete base, sin embargo, es más simple y rápido (está escrito en C++).
Todas las funciones del paquete tiene la particularidad de que su primer argumento es un data frame al que le realizará la operación, mientras que los subsiguiente argumentos describen como realizar tal operación.
Finalmente el resultado de todas estas funciones es un nuevo data frame. Esto no ocurre con las funciones de base.
Base R vs. Tidyverse

Instalar y cargar dplyr
- La instalación es por única vez en una computadora.
# install.packages("dplyr") # ya lo tengo instalado- Comenté esa línea porque ya lo tengo instalado
Instalar y cargar dplyr
- La instalación es por única vez en una computadora.
# install.packages("dplyr") # ya lo tengo instalado- Comenté esa línea porque ya lo tengo instalado
- En cada nueva sesión de RStudio lo debo cargar para poder usar sus funciones
library(dplyr)Notar que en la función de instalación el nombre del paquete se escribe entre comillas pero en la función de carga va sin comillas. No hagas library("dplyr").
Manipular datos
- Seleccionar columnas/variables
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
- Crear nuevas variables
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
- Crear nuevas variables
- Filtrar o eliminar observaciones
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
- Crear nuevas variables
- Filtrar o eliminar observaciones
- Chequear existencia de observaciones duplicadas
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
- Crear nuevas variables
- Filtrar o eliminar observaciones
- Chequear existencia de observaciones duplicadas
- Chequear existencia de datos faltantes
Manipular datos
- Seleccionar columnas/variables
- Cambiar nombre de variables
- Transformar variables
- Crear nuevas variables
- Filtrar o eliminar observaciones
- Chequear existencia de observaciones duplicadas
- Chequear existencia de datos faltantes
- Reestructurar los datos
dplyr::select()
Seleccionar columnas/variables
- La función select() selecciona columnas de un data frame
Seleccionar columnas/variables
- La función select() selecciona columnas de un data frame
- El primer argumento es el data frame y luego la(s) variable(s) separadas por coma.
Seleccionar columnas/variables
- La función select() selecciona columnas de un data frame
- El primer argumento es el data frame y luego la(s) variable(s) separadas por coma.
select(<dataframe>, <variable>)
Seleccionar columnas/variables
- La función select() selecciona columnas de un data frame
- El primer argumento es el data frame y luego la(s) variable(s) separadas por coma.
select(<dataframe>, <variable>)select(ech19, numero)# A tibble: 107,871 x 1numero<chr>1 20190000012 20190000013 20190000024 20190000025 20190000036 20190000037 20190000048 20190000049 201900000510 2019000005# … with 107,861 more rowsselect(ech19, numero, nper)# A tibble: 107,871 x 2numero nper<chr> <dbl>1 2019000001 12 2019000001 23 2019000002 14 2019000002 25 2019000003 16 2019000003 27 2019000004 18 2019000004 29 2019000005 110 2019000005 2# … with 107,861 more rows
Las funciones de tidyverse permiten llamar a las variables de un data frame sin usar comillas pero esto no es aplicable al resto de los paquetes de R, incluido los del base.
Seleccionar columnas/variables
Seleccionar un rango de columnas: select(<df>, <desde>:<hasta>)
select(ech19, dpto:region_3)Seleccionar todas las columnas menos una: select(<df>, -<variable>)
select(ech19, -nper)dplyr::slice()
Seleccionar filas/observaciones por su posición
- La función slice() selecciona observaciones/filas según su posición.
Seleccionar filas/observaciones por su posición
- La función slice() selecciona observaciones/filas según su posición.
- Esto no es robusto a un reordenamiento de las observaciones. Sirve para "ver" algunos casos.
Seleccionar filas/observaciones por su posición
- La función slice() selecciona observaciones/filas según su posición.
- Esto no es robusto a un reordenamiento de las observaciones. Sirve para "ver" algunos casos.
slice(<df>, <nro_fila>, <nro_fila>)
Seleccionar filas/observaciones por su posición
- La función slice() selecciona observaciones/filas según su posición.
- Esto no es robusto a un reordenamiento de las observaciones. Sirve para "ver" algunos casos.
slice(<df>, <nro_fila>, <nro_fila>)# selecciono las filas 1 y 5slice(ech19, 1, 5)
# selecciono las filas de 1 a 5slice(ech19, 1:5)dplyr::filter()
Selecciona observaciones según condición
- La función filter() selecciona observaciones/filas según una condición.
Selecciona observaciones según condición
- La función filter() selecciona observaciones/filas según una condición.
- Puede ser una condición que involucre a una o varias variables. Condiciono a que tome o no tome ciertos valores.
Selecciona observaciones según condición
- La función filter() selecciona observaciones/filas según una condición.
- Puede ser una condición que involucre a una o varias variables. Condiciono a que tome o no tome ciertos valores.
filter(<df>, <condicion>)
Selecciona observaciones según condición
- La función filter() selecciona observaciones/filas según una condición.
- Puede ser una condición que involucre a una o varias variables. Condiciono a que tome o no tome ciertos valores.
filter(<df>, <condicion>)mdeo <- filter(ech19, dpto == 1) # me quedo con los casos de Montevideohead(mdeo)
# A tibble: 6 x 9 numero nper dpto nomdpto region_3 e26 e27 ht19 pobpcoac <chr> <dbl> <dbl+lbl> <chr> <dbl+lbl> <dbl+l> <dbl> <dbl> <dbl+lbl>1 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 32 2 2 [Ocupado…2 2019000… 2 1 [Montev… MONTEVI… 1 [Montev… 1 [Hom… 9 2 1 [Menores…3 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 53 2 2 [Ocupado…4 2019000… 2 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 13 2 1 [Menores…5 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 85 1 10 [Inactiv…6 2019000… 1 1 [Montev… MONTEVI… 1 [Montev… 2 [Muj… 45 1 2 [Ocupado…Operadores comparativos
Operadores de comparación
Mayor que: >
filter(ech19, e27 > 90) # personas mayores de 90Mayor igual que: >=
filter(ech19, e27 >= 90) # personas mayores de 90 o masOperadores de comparación
Menor que: <
filter(ech19, e27 < 10)Menor igual que: <=
filter(ech19, e27 <= 10)Operadores de comparación
Igual que: ==
filter(ech19, e27 == 90)Diferente que: !=
filter(ech19, e27 != 90)Operadores lógicos
Operadores lógicos
O lógico: |
# selecciono personas menores a 10 o mayores a 90filter(ech19, e27 < 10 | e27 > 90)Operadores lógicos
Y lógico: &
# selecciono menores a 10 y de Saltofilter(ech19, e27 < 10 & nomdpto == "FLORES")Operadores lógicos
Y lógico: &
# selecciono menores a 10 y de Saltofilter(ech19, e27 < 10 & nomdpto == "FLORES")Operadores lógicos
No lógico: !
# selecciono todas las personas que no tienen 90 filter(ech19, !e27 == 90)%in%
Operador %in%
- Compara cada elemento de un vector con los elementos de otro vector.
Operador %in%
- Compara cada elemento de un vector con los elementos de otro vector.
- <x> %in% <y>, el primer elemento de x se compara con todos los elementos de y, el segundo elemento de x se compara con todos los elementos de y, así sucesivamente.
Operador %in%
- Compara cada elemento de un vector con los elementos de otro vector.
- <x> %in% <y>, el primer elemento de x se compara con todos los elementos de y, el segundo elemento de x se compara con todos los elementos de y, así sucesivamente.
- Devuelve un TRUE o un FALSE en cada comparación. TRUE cuando el elemento de x está en y, FALSE en caso contrario.
Operador %in%
- Compara cada elemento de un vector con los elementos de otro vector.
- <x> %in% <y>, el primer elemento de x se compara con todos los elementos de y, el segundo elemento de x se compara con todos los elementos de y, así sucesivamente.
- Devuelve un TRUE o un FALSE en cada comparación. TRUE cuando el elemento de x está en y, FALSE en caso contrario.
- Cuando lo uso en filter() se queda con los TRUE.
# selecciono personas Durazno y Rochafilter(ech19, nomdpto %in% c("DURAZNO", "ROCHA"))En este caso es lo mismo que:
# selecciono alojamientos menor a 60 y que el tipo sea Private room filter(ech19, nomdpto == "DURAZNO" | nomdpto == "ROCHA")Ejercicio (10')
Selecciona los casos que tienen entre 3 y 5 años de edad y guarda en un objeto llamado
menores_3_5. La variable e27 es la edad.Selecciona los casos cuya vivienda tiene 4 o 6 habitaciones y guarda en un objeto llamado
habitaciones_4. La variable d9 es el número de habitaciones.
- Selecciona los últimos 5 casos de ech19 y guarda en un objeto llamado
ultimos_5.
Selecciona un registro por hogar y guarda en un objeto llamado
hogares.¿De cuál departamento es el hogar con mayor cantidad de personas? Ver ?slice_max
dplyr::arrange()
Ordenar las observaciones según una variable
ech19 <- select(ech19, ht11, numero, nomdpto)La función arrange() ordena un data frame de acuerdo a una(s) variable(s) de manera creciente por defecto.
Ordenar las observaciones según una variable
ech19 <- select(ech19, ht11, numero, nomdpto)La función arrange() ordena un data frame de acuerdo a una(s) variable(s) de manera creciente por defecto.
arrange(ech19, ht11)Ordenar las observaciones según una variable
ech19 <- select(ech19, ht11, numero, nomdpto)La función arrange() ordena un data frame de acuerdo a una(s) variable(s) de manera creciente por defecto.
arrange(ech19, ht11)Para ordenar de manera decreciente debo incluir la función desc():
arrange(ech19, desc(ht11))Ordenar las observaciones según una variable
ech19 <- select(ech19, ht11, numero, nomdpto)La función arrange() ordena un data frame de acuerdo a una(s) variable(s) de manera creciente por defecto.
arrange(ech19, ht11)Para ordenar de manera decreciente debo incluir la función desc():
arrange(ech19, desc(ht11))Para ordenar por más de una variable:
arrange(ech19, desc(ht11), e27)dplyr::summarise()
Calcular un resumen de una variable
La función summarise() o summarize() calcula un resumen de variables
summarise(<df>, <column> = <function>(<variable>))
El resultado será una data frame con una fila, a menos que los datos estén agrupados, y una columna por cada estadístico de resumen.
summarise(ech19, promedio = mean(ht19))- Se puede utilizar cualquier función que cumpla con que lo datos de entrada sean numéricos y como salida se entregue una constante. Por ejemplo las funciones de resumen que vimos de R base:
mean(),max(),min(),median(),var(),sd(),sum(), etc. Existen otras específicas dedplyrque iremos viendo.
Calcular un resumen de una variable
- Se pueden aplicar diferentes funciones a la misma o diferentes variables
# la función n() devuelve la cantidad de observacionessummarise(ech19, promedio = mean(ht19), varianza = var(ht19), total = n())- Suele ser más claro escribirlo hacia abajo
summarise(ech19, promedio = mean(ht19), varianza = var(ht19), total = n())dplyr::count()
Cálculo frecuencias de una variable
- La función count() es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
Cálculo frecuencias de una variable
- La función count() es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
- count(<df>, <variable>)
Cálculo frecuencias de una variable
- La función count() es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
- count(<df>, <variable>)
- En R base usamos table() pero el resultado no es un data frame y la salida no es muy amigable.
Cálculo frecuencias de una variable
- La función count() es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
- count(<df>, <variable>)
- En R base usamos table() pero el resultado no es un data frame y la salida no es muy amigable.
Cálculo frecuencias de una variable
- La función count() es la función de dplyr para hacer una tabla de frecuencias, el resultado es siempre un data frame de menor dimensión que el original.
- count(<df>, <variable>)
- En R base usamos table() pero el resultado no es un data frame y la salida no es muy amigable.
count(ech19, region_3)# A tibble: 3 x 2 region_3 n <dbl+lbl> <int>1 1 [Montevideo] 382072 2 [Interior - Localidades de 5000 habitantes o más] 508543 3 [Interior - Localidades de menos de 5000 habitantes y zona ru] 18810Cálculo frecuencias entre dos variables
count(ech19, region_3, e26)# A tibble: 6 x 3 region_3 e26 n <dbl+lbl> <dbl+lbl> <int>1 1 [Montevideo] 1 [Hombr… 173972 1 [Montevideo] 2 [Mujer] 208103 2 [Interior - Localidades de 5000 habitantes o más] 1 [Hombr… 238604 2 [Interior - Localidades de 5000 habitantes o más] 2 [Mujer] 269945 3 [Interior - Localidades de menos de 5000 habitantes y zona … 1 [Hombr… 93486 3 [Interior - Localidades de menos de 5000 habitantes y zona … 2 [Mujer] 9462dplyr::mutate()
Calculo una nueva variable
- La función mutate() permite calcular nuevas variables
Calculo una nueva variable
- La función mutate() permite calcular nuevas variables
- mutate(<df>, <nombre> = <calculo>)
Calculo una nueva variable
- La función mutate() permite calcular nuevas variables
- mutate(<df>, <nombre> = <calculo>)
- El resultado será de la misma cantidad de observaciones que el data frame original
Calculo una nueva variable
- La función mutate() permite calcular nuevas variables
- mutate(<df>, <nombre> = <calculo>)
- El resultado será de la misma cantidad de observaciones que el data frame original
- Conviene guardarlo en el mismo objeto (data frame original)
Calculo una nueva variable
- La función mutate() permite calcular nuevas variables
- mutate(<df>, <nombre> = <calculo>)
- El resultado será de la misma cantidad de observaciones que el data frame original
- Conviene guardarlo en el mismo objeto (data frame original)
ech19 <- mutate(ech19, media_edad = mean(e27))head(ech19$media_edad)[1] 39.87829 39.87829 39.87829 39.87829 39.87829 39.87829dplyr::case_when()
Crear una variable a partir de varias condiciones
La función case_when() permite calcular una nueva variable a partir de condicionar los valores de otra
ech19 <- mutate(ech19, mayor = case_when( e27 < 18 ~ "Menor", e27 >= 18 ~ "Mayor"))Agrupo los casos por cierta variable
- La función group_by() permite agrupar las observaciones por cierta variable.
Agrupo los casos por cierta variable
- La función group_by() permite agrupar las observaciones por cierta variable.
- Permite hacer operaciones por grupos para posteriormente realizar otros cálculos.
Agrupo los casos por cierta variable
- La función group_by() permite agrupar las observaciones por cierta variable.
- Permite hacer operaciones por grupos para posteriormente realizar otros cálculos.
- group_by(<df>, <variable>)
Agrupo los casos por cierta variable
- La función group_by() permite agrupar las observaciones por cierta variable.
- Permite hacer operaciones por grupos para posteriormente realizar otros cálculos.
- group_by(<df>, <variable>)
# promedio de precio por barrioech19_gr <- group_by(ech19, nomdpto)summarise(ech19_gr, promedio = mean(ht19))# A tibble: 19 x 2 nomdpto promedio <chr> <dbl> 1 ARTIGAS 3.70 2 CANELONES 3.38 3 CERRO LARGO 3.25 4 COLONIA 3.12 5 DURAZNO 3.68 6 FLORES 3.23 7 FLORIDA 3.19 8 LAVALLEJA 3.26 9 MALDONADO 3.2510 MONTEVIDEO 3.2111 PAYSANDU 3.4612 RIO NEGRO 3.4013 RIVERA 3.4314 ROCHA 3.1115 SALTO 3.8016 SAN JOSE 3.3917 SORIANO 3.4218 TACUAREMBO 3.4519 TREINTA Y TRES 3.24Agrupo los casos por cierta variable
- También lo puedo hacer concatenando funciones
summarise(group_by(ech19, nomdpto), promedio = mean(ht19))# A tibble: 19 x 2 nomdpto promedio <chr> <dbl> 1 ARTIGAS 3.70 2 CANELONES 3.38 3 CERRO LARGO 3.25 4 COLONIA 3.12 5 DURAZNO 3.68 6 FLORES 3.23 7 FLORIDA 3.19 8 LAVALLEJA 3.26 9 MALDONADO 3.2510 MONTEVIDEO 3.2111 PAYSANDU 3.4612 RIO NEGRO 3.4013 RIVERA 3.4314 ROCHA 3.1115 SALTO 3.8016 SAN JOSE 3.3917 SORIANO 3.4218 TACUAREMBO 3.4519 TREINTA Y TRES 3.24Agrupo los casos por cierta variable
- También lo puedo hacer concatenando funciones
summarise(group_by(ech19, nomdpto), promedio = mean(ht19))# A tibble: 19 x 2 nomdpto promedio <chr> <dbl> 1 ARTIGAS 3.70 2 CANELONES 3.38 3 CERRO LARGO 3.25 4 COLONIA 3.12 5 DURAZNO 3.68 6 FLORES 3.23 7 FLORIDA 3.19 8 LAVALLEJA 3.26 9 MALDONADO 3.2510 MONTEVIDEO 3.2111 PAYSANDU 3.4612 RIO NEGRO 3.4013 RIVERA 3.4314 ROCHA 3.1115 SALTO 3.8016 SAN JOSE 3.3917 SORIANO 3.4218 TACUAREMBO 3.4519 TREINTA Y TRES 3.24- En la línea anterior anidamos funciones para obtener el promedio según barrios.
- La anidación de funciones tiende a volver confuso el código...veremos luego cómo superar este inconveniente con el operador
%>%.
Ejercicio (5')
Calcular el promedio de edad según sexo.
Calcular la cantidad de jefas de hogar.
Trabajar en proyecto
Permite ordenar los diferentes archivos de un análisis y prescindir de usar setwd() y/o escribir rutas larguísimas.
Si el archivo tesis.Rproj está ubicado en: /home/calcita/Escritorio/tesis, todos los archivos que estén en la carpeta tesis voy a poder cargarlos sin definir una ruta del archivo.
load("datos.csv")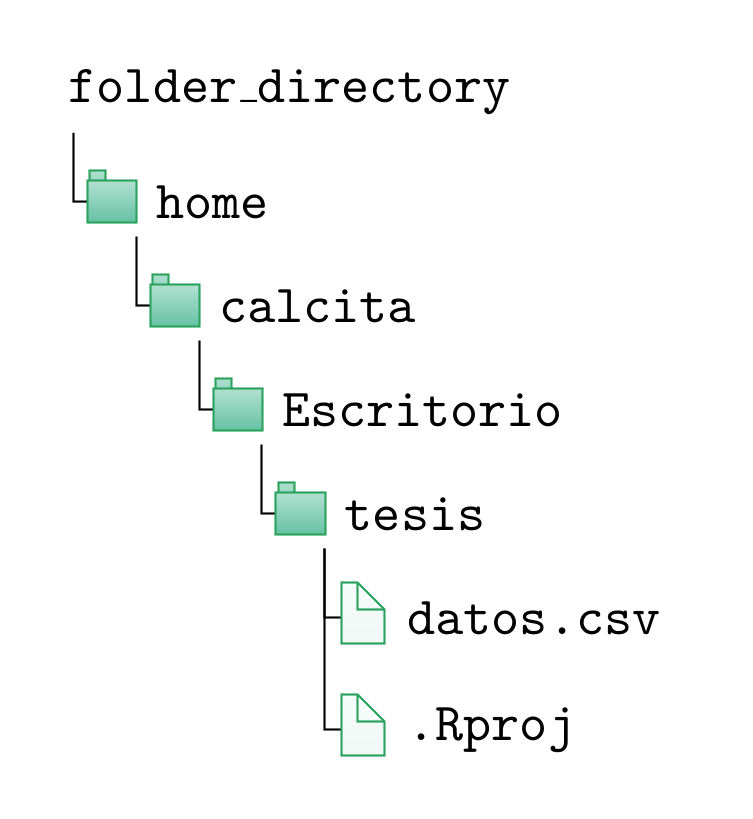
Crear proyecto
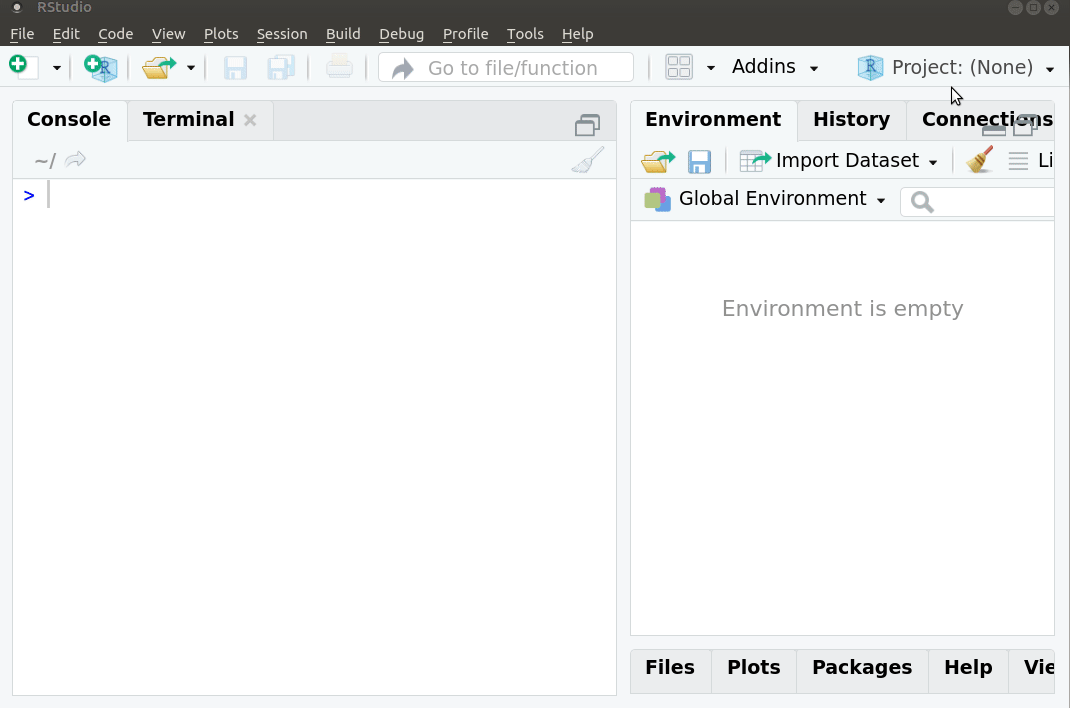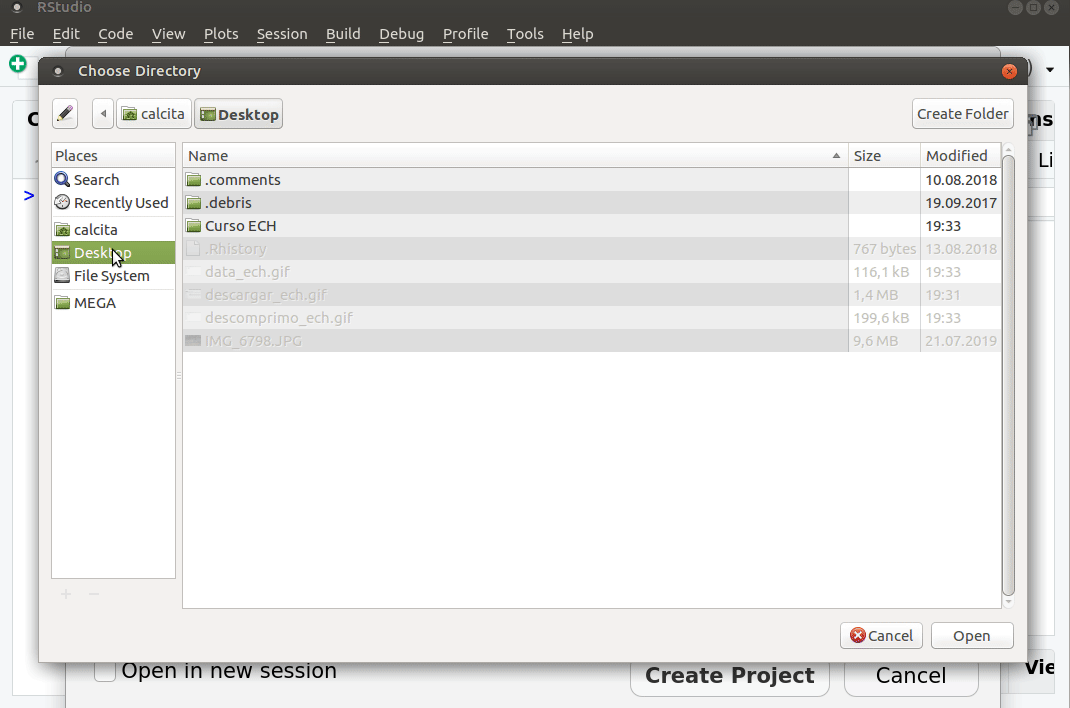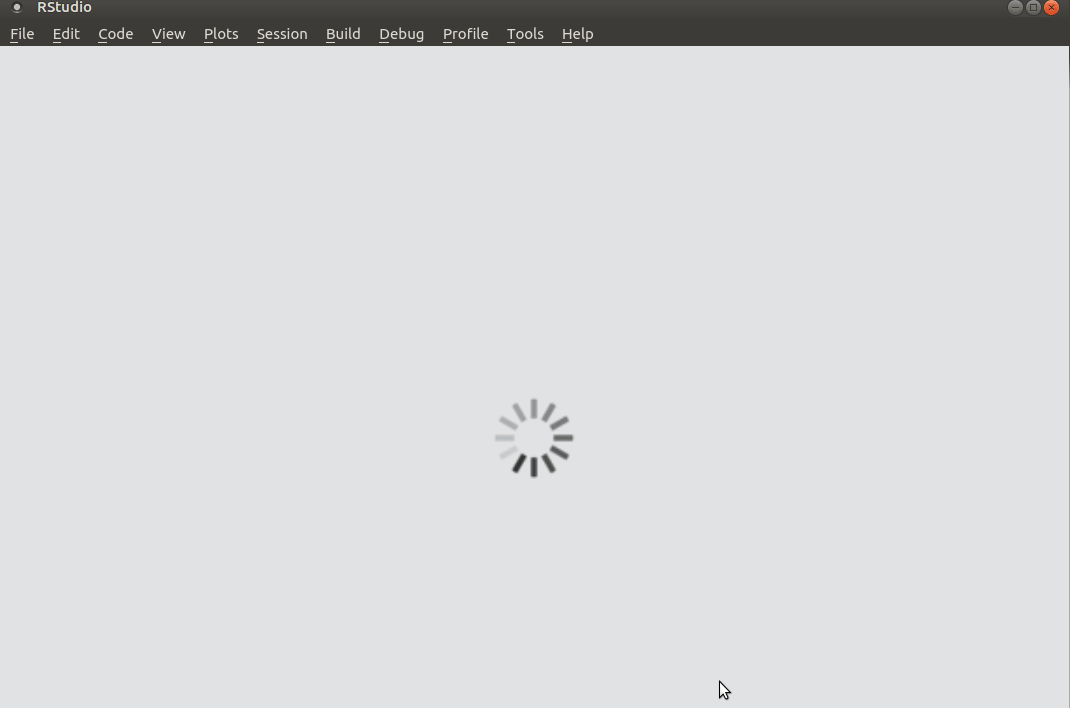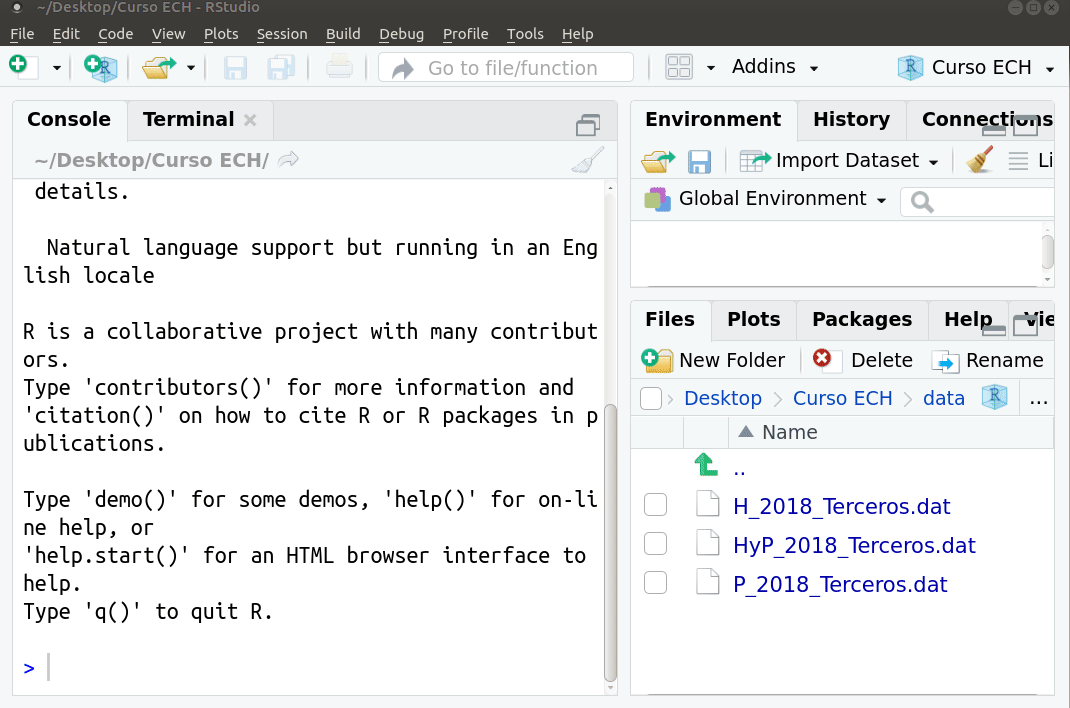
Abrir proyecto
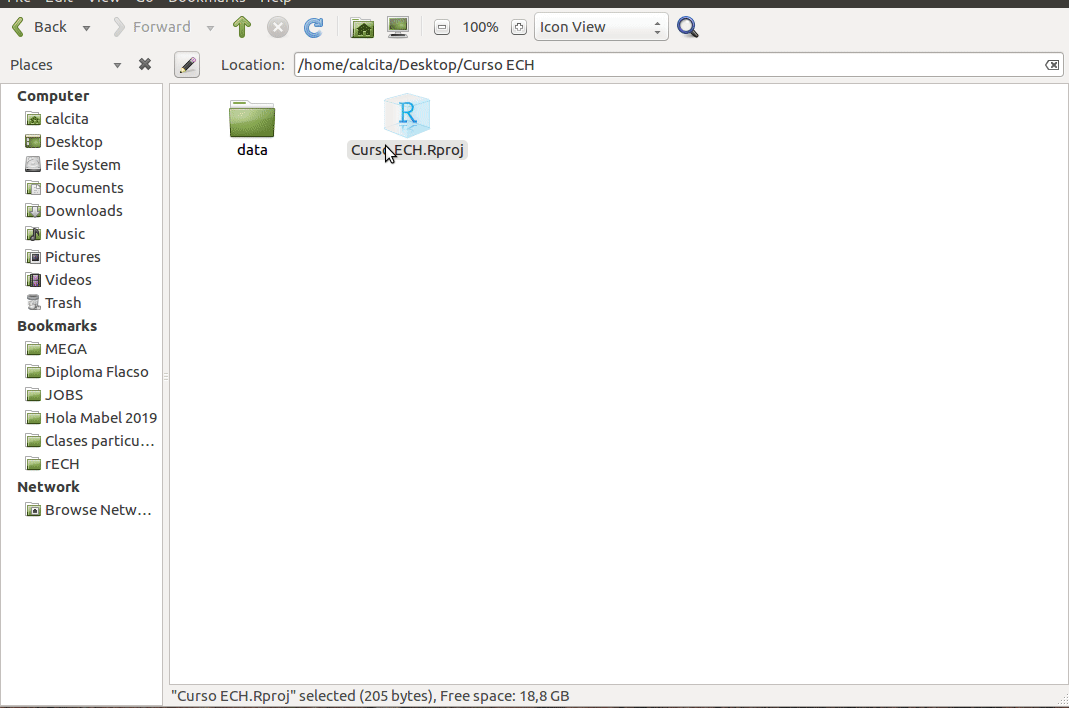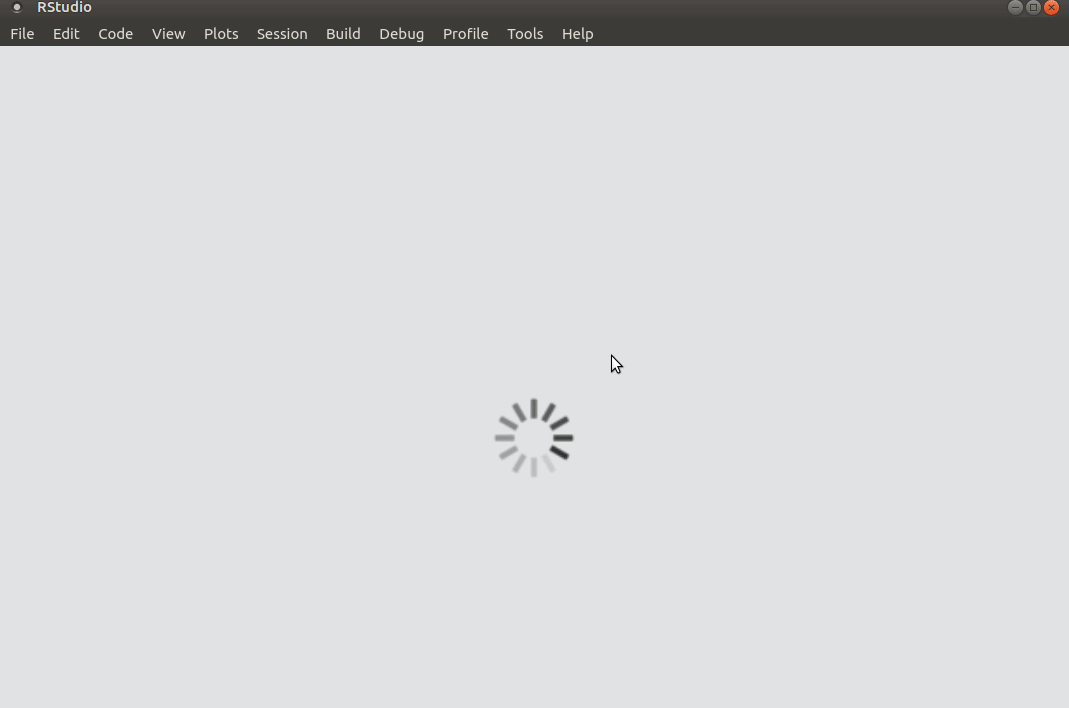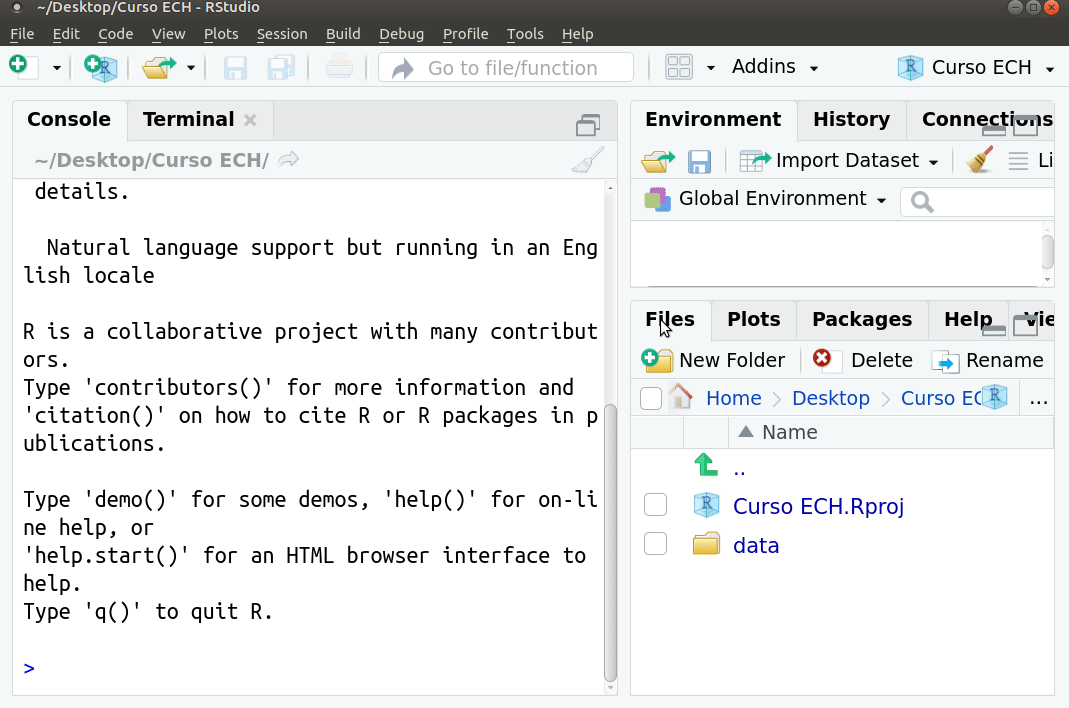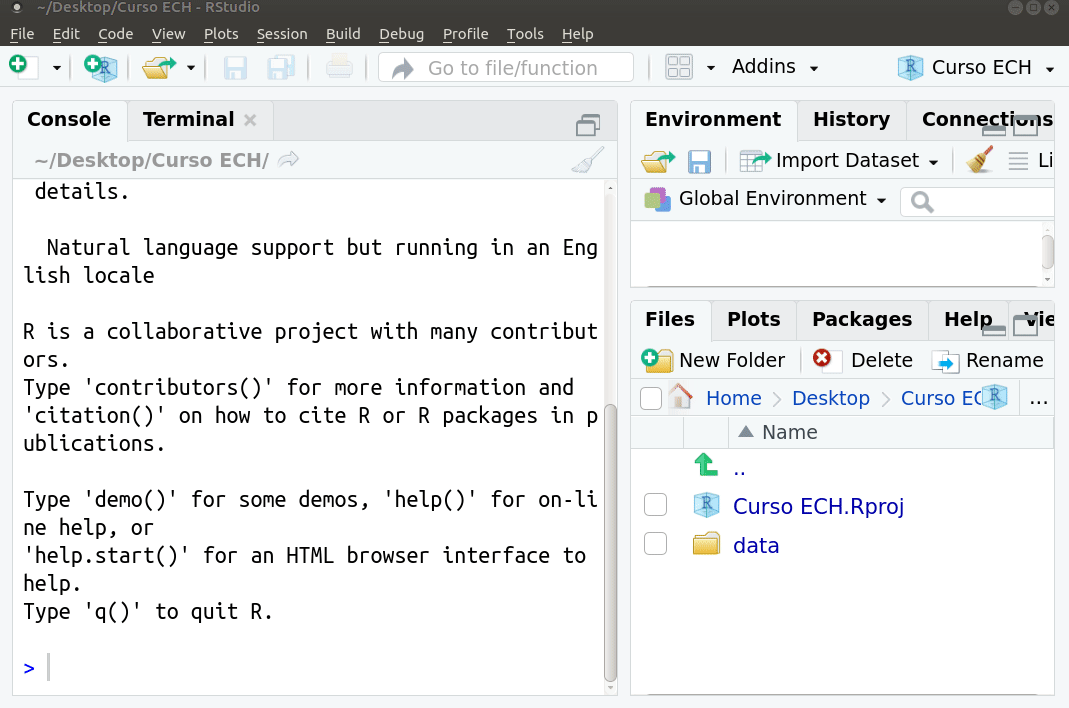
Crear script
Ejercicio (5')



Crear una carpeta llamada "Curso ECH"
Abrir Rstudio y crear un proyecto. Elegir como directorio la carpeta recién creada.
Crear un script de R donde guardaremos el código de este taller. Agregar a la carpeta los materiales del curso.